Information Theory A Tutorial Introduction – James V Stone
in Blog
Our hero, Shrek, was just one step away from saving princess Fiona and getting his beloved swamp back. However, the gate to the highest tower in the castle, where the princess was imprisoned, was guarded by a mighty Dragon. Fortunately, considered herself as an intellectual, Dragon refuses a battle of life and death, instead, she gave Shrek a puzzle to solve in order to pass through the door. It is as follows:
Given a 4×4 square (a) as below and a palette of 4 different colours represented as 4 different digits, can you produce the shortest sequence of digits such that I can perfectly reconstruct the square from?
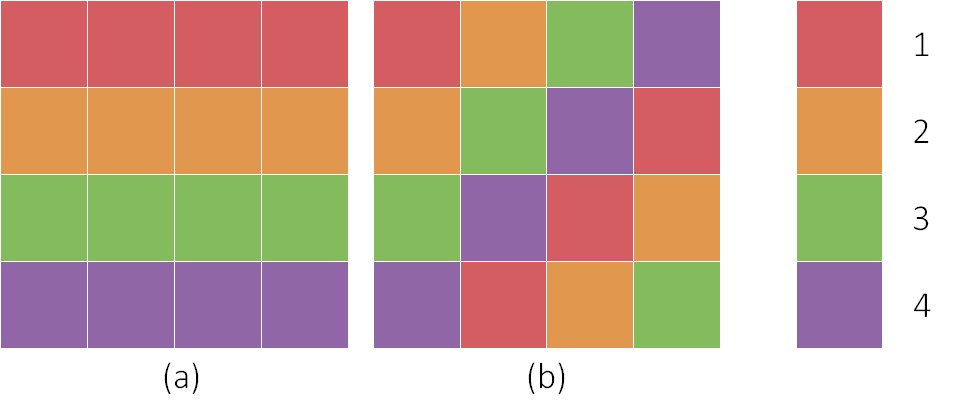
At first glance, a natural solution would be ‘1111 2222 3333 4444′ to list out the value of each cell from left to right, top to bottom. After pondering for a while, Shrek came up with a more brilliant idea, which first named the value colour then followed by its frequency, in the same ordering. Simply put, the sequence now was ‘14 24 34 44‘. Nodded her head pleasantly, Dragon stepped asides and allowed Shrek to pass through…
Actually, on the previous day, Dragon asked another knight a similar question, but with the square (b), and obviously he had failed. Shrek’s solution in that case is worse than the first solution(‘11213141 21314111 31411121 41112131‘), and it is a bit trickier to solve.
The above puzzle gives us an interesting observation: both squares have the same number of red, orange, green and purple boxes, yet their corresponding shortest sequences are represented differently. In other words, with a same amount of information, how could they not be represented as the same length? Does there exist an optimal encoding scheme for both cases?
It turns out, information can be quantified to justify whether a representation is optimally encoded(represented) or not. Information Theory A Tutorial Introduction – James V Stone captures such question and beyond. This post is an attempt to provide a big picture of what the book covers.
Information is measured in bits or Shannon information, with one bit is the amount of information to choose between two equally probable alternatives. In other words, if one has n bits of information, she can choose from m = 2^n equally probable alternatives. This implies a strong implication. since with only 20 bits, you can represent 1 048 576 events. It’s noteworthy to mention this only holds so long as all the events are equally probable.
Each bit has only two states, hence can be encoded as boolean value True and False; or binary digits 0 and 1. People tend to use bit in binary digit and bit in information interchangeably, though it is true in most case, one should be wary of the distinction. The former must always be an integer, whereas the latter can be real, or even negative in the continuous random variable case.
A typical framework of information theory is the communication channel, where the terms are coined accordingly, to formulate the conservation of information in the lossless and lossy environment. Such formulation is chosen to frame other related tasks, for instance Statistical Machine Translation with input is sentence in English and output is the French counterpart. Formally, a source generates message s containing k symbols. Prior to be put to the input channel, we encode the message to a sequence of code words based on a code book, a 1-to-1 mapping function. Throughout the channel, there may be noise injected to the sequence, hence the reconstruction process of the original value of message s is error-prone. Notably, the channel always has a predetermined capacity, which is the maximum amount of information (bit per code word) can go through in a time unit.
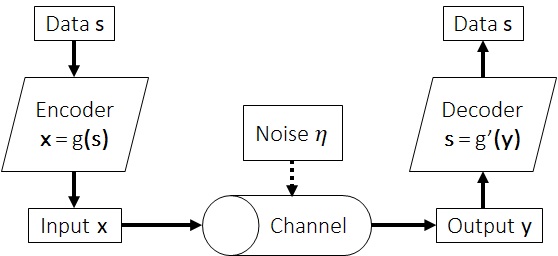
To analyse this framework, there are 2 primary perspectives: the random variable nature (symbols in the message) and the transmission process nature (lossless or lossy environment, caused by the presence of noise).
First, a discrete random variable has a finite number of possible values, and its information is quantified in terms of entropy, the average of surprisal of that variable, i.e. expected logarithm of 1 over probability of the value. This quantity reaches it maximum when all the values are equally probable, which coincides with the definition of bit. Alternatively, the uncertainty has similar interpretation, e.g. the more probable a value to occur, the less surprised it is; hence the gap between the entropy of the data after and before going through the channel is called information gain or mutual information.
On the other hand, it is nontrivial to measure entropy of a continuous random variable, in case of temperature or wave in radio transmission. One way is discretising the value range to finite bins, but as the grainier the number of bins is, the entropy converses to infinity, which is meaningless. Similarly, a differential entropy suffers the same disadvantage, thus one way is cutting off the term causing infinity and use the rest as approximation. Fortunately, we usually care more about the mutual information, which is the gap between two entropies, hence the annoying terms automatically cancel out each other and no approximation loss incurs.
Second, a noiseless channel can fully utilise the channel capacity for efficient encoding, whereas a noisy one must spare some space for error-correcting code to detect and fix fautly transmitted code words. Any remainder amount after subtracting two entropies of input and output, together with the mutual information, is the amount of noise in the channel.
In real life application, it is essential to know the channel capacity, since it tells us how an encoding scheme can best perform with respect to the random variable under consideration. It gives us a hint how far we can make, but provides no guidance how to achieve. In the ideal case, a fair 8-sided die encodes its value in 3 binary digits to transmit would achieve this. However, natural distribution is often not independent and uniform to have equally probable value, consequently overestimating its entropy and channel capacity. To avoid that, we must ensure or transform the distribution of random variable to be independent and identically distributed. Once such requirement obtained, proposed encoding schemes (e.g. Huffman coding) would have the best coding efficiency, or shortest sequence to represent the square in the puzzle at the beginning.
Taking words in a document as the discrete random variable. The presence of the phrase “the cat and” entails a high probability of a noun follows, hence does not meet the independence conditional. One can force this by instead word, choose phrase of n-words as random variable. It has been shown with a 10-word phrase, they are nearly independent and have entropy converge to the channel capacity.
The continuous variable is more challenging, since it has infinite values. Fortunately, there are rules of thump to handle this, according to the information we have of the underlying distribution. For instance, if the variable has both the upper and lower bounds, uniform distribution is the best encoding scheme. The remaining question is, how can one transform an arbitrary distribution to the optimal one. The book will help you answer this.
As one last side note, from the Machine Learning’s point of view, the mutual information plays an important role. For two given variables, mutual information can tell how strong their correlation are, despite whether it is a linear or nonlinear relationship, which is way more helpful than the correlation coefficient widely used. Furthermore, the mutual information between variable X and Y, when expressed in terms of Bayes’ rule, is in fact the expected Kullback-Leiber divergence between the posterior, p(X \vert Y), and prior, p(X).
The book will cover more details of what I have explained here, including the different properties of disrete and continuous random variable in terms of entropy, formulation analysis of entropy in both cases, and interpretations of natural phenomena from Information Theorey perspective. Personally, this is a good introductory book and it satisfies my initial motivation in looking for Information Theory’s connection to Machine Learning.